|
Shuaiyi Huang I am a Research Engineer at META FAIR Robotics, World Modeling Team. I obtained my PhD degree in Computer Science from University of Maryland, College Park, advised by Prof. Abhinav Shrivastava. I obtained my M.S. degree in Computer Science from ShanghaiTech University in 2020, advised by Prof. Xuming He. I received my B.Eng. degree in Software Engineering from Tongji University in 2017.
My research lies in the intersection of Computer Vision and Autonomous Agents, with a focus on video understanding, object recognition, policy learning, and generative world modeling. I aim to build foundation models that seamlessly integrate visual, linguistic, and action understanding for real-world applications. |

|
Experiences
|
Publications |

|
Trokens: Semantic-Aware Relational Trajectory Tokens for Few-Shot Action Recognition
Pulkit Kumar*, Shuaiyi Huang*, Matthew Walmer, Sai Saketh Rambhatla, Abhinav Shrivastava ICCV, 2025 project page / paper / code Semantic sampling of query points for tracking with explicit motion modeling improves few-shot video action recognition. |
|
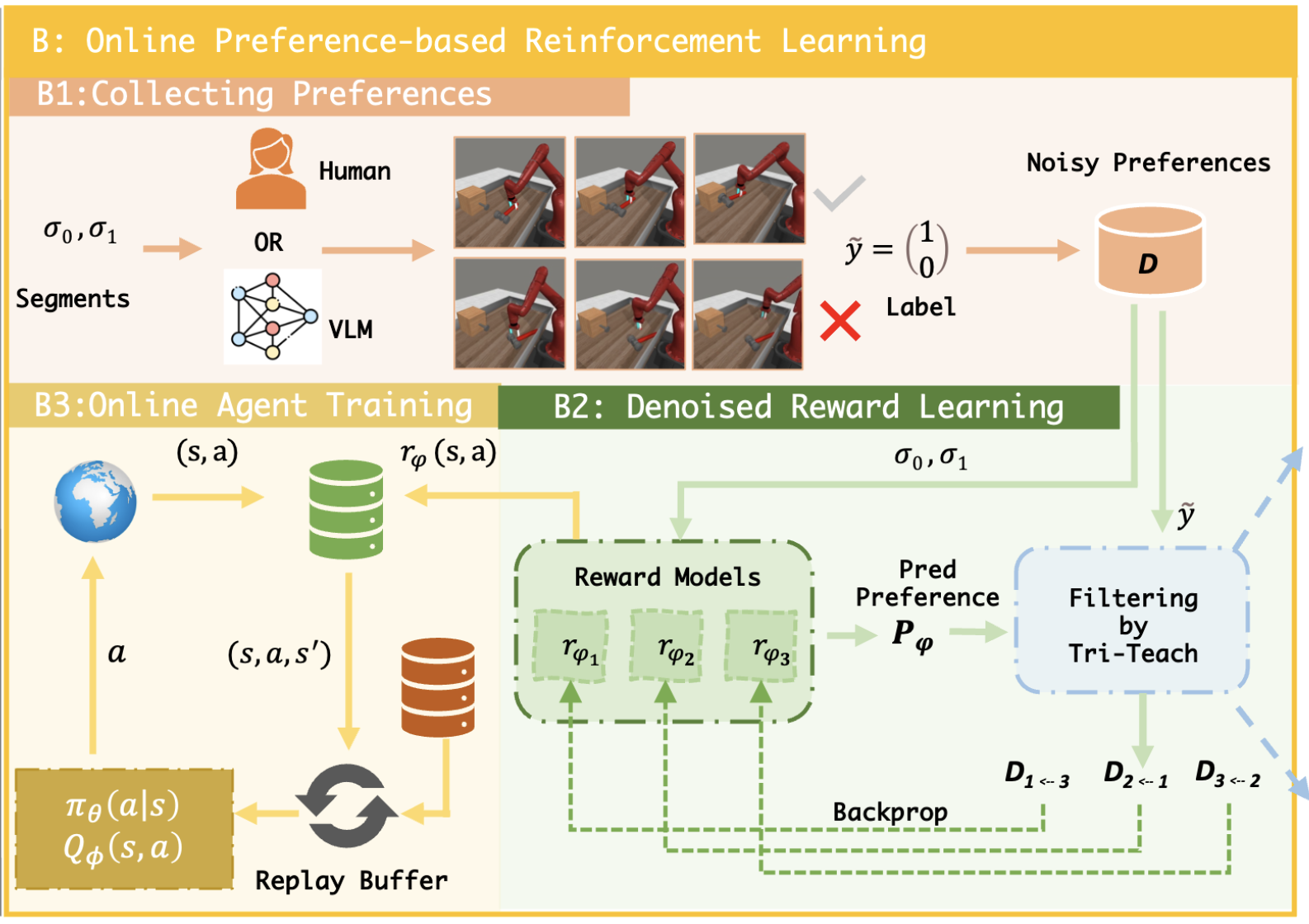
TREND: Tri-teaching for Robust Preference-based Reinforcement Learning with Demonstrations
Shuaiyi Huang, Mara Levy, Anubhav Gupta, Daniel Ekpo, Ruijie Zheng, Abhinav Shrivastava ICRA, 2025 project page / paper Preference feedback collected by human or VLM annotators is often noisy, presenting a significant challenge for preference-based reinforcement learning. To address this challenge, we propose TREND, a novel framework that integrates few-shot expert demonstrations with a tri-teaching strategy for effective noise mitigation. |
|
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Ruijie Zheng*, Yongyuan Liang*, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, Jianwei Yang ICLR, 2025 project page / arxiv / code In this work, we introduce visual trace prompting, a simple yet effective approach to facilitate Vision Language Action Models' spatial- temporal awareness for action prediction. visually. |
|
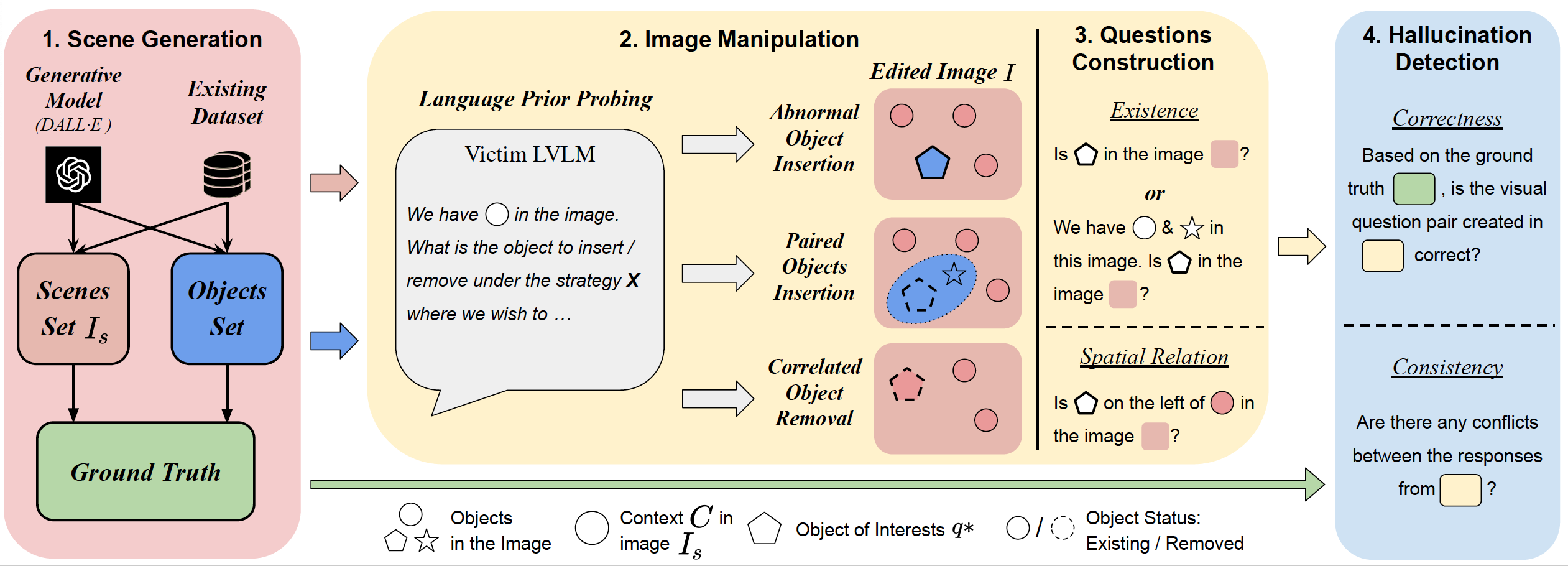
AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
Xiyang Wu*, Tianrui Guan*, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shrivastava, Furong Huang, Jordan Lee Boyd-Graber, Tianyi Zhou, Dinesh Manocha EMNLP, 2024 arxiv / code A benchmark framework that automatically generates hallucination cases in Vision-Language models to evaluate their robustness and accuracy. |
|
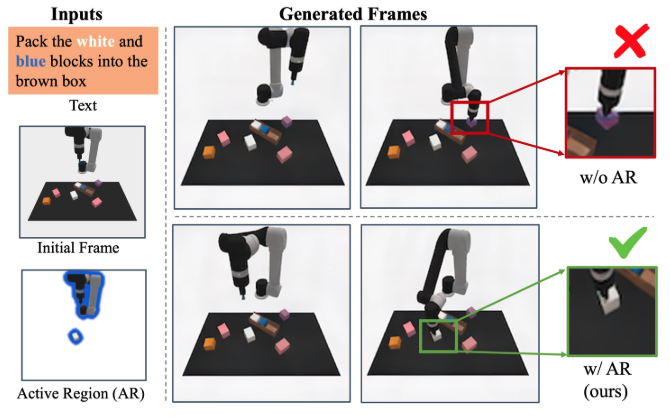
ARDuP: Active Region Video Diffusion for Universal Policies
Shuaiyi Huang, Mara Levy, Zhenyu Jiang, Anima Anandkumar, Yuke Zhu, Linxi Fan, De-An Huang, Abhinav Shrivastava IROS, 2024 (Oral Presentation) arxiv / code We propose a novel method for universal policy learning via active region video diffusion models, focusing on task-critical regions in videos. |

|
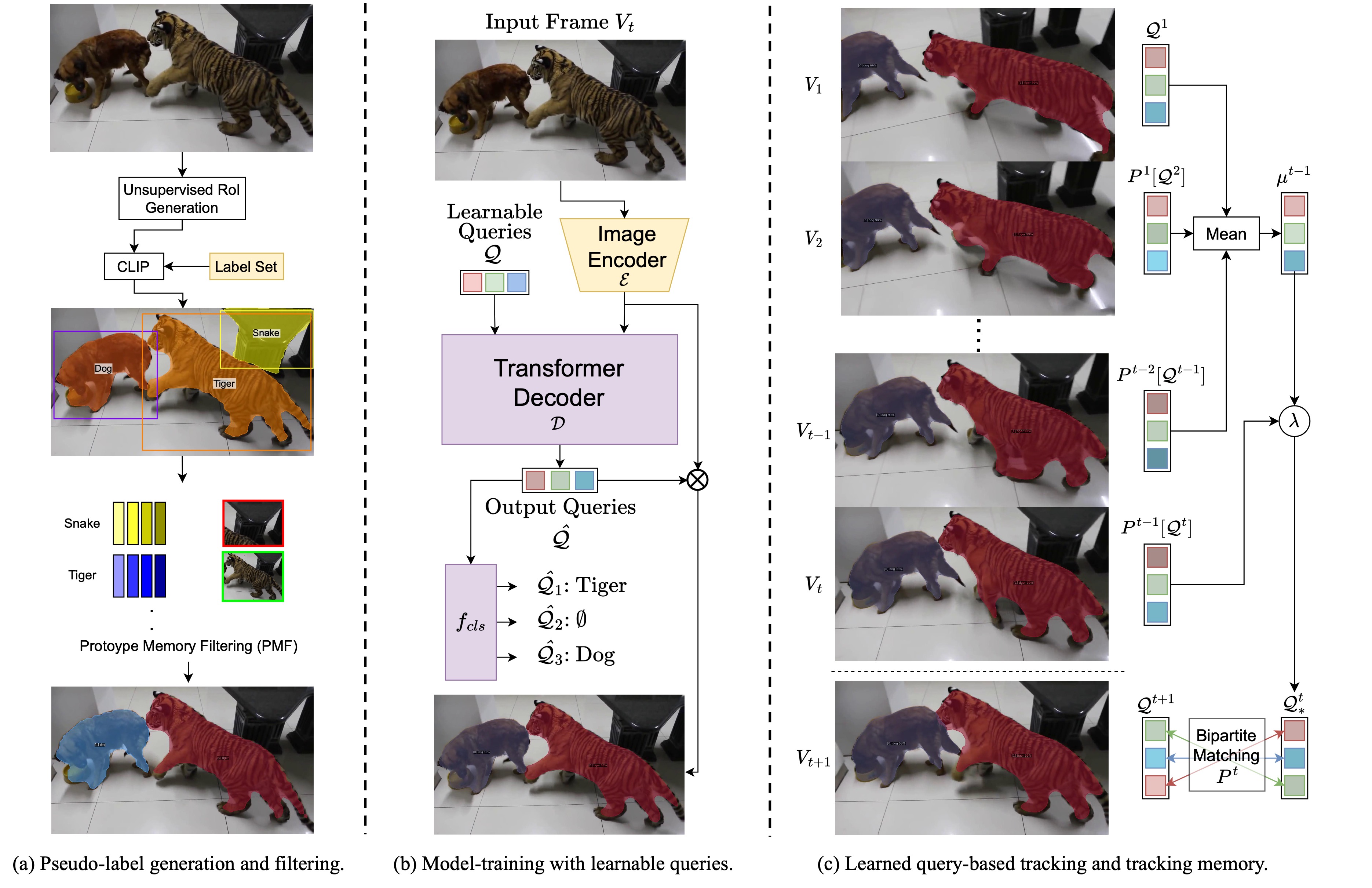
What is Point Supervision Worth in Video Instance Segmentation?
Shuaiyi Huang, De-An Huang, Zhiding Yu, Shiyi Lan, Subhashree Radhakrishnan, Jose M. Alvarez, Abhinav Shrivastava, Anima Anandkumar CVPR Workshop, 2024 arxiv This work explores the impact of point-level supervision in the context of video instance segmentation, offering insights into its effectiveness. |
|
UVIS: Unsupervised Video Instance Segmentation
Shuaiyi Huang, Saksham Suri, Kamal Gupta, Sai Saketh Rambhatla, Ser-nam Lim, Abhinav Shrivastava CVPR Workshop, 2024 arxiv We propose an unsupervised approach for video instance segmentation, leveraging self-supervised learning methods to improve object instance tracking and segmentation across video frames. |
|
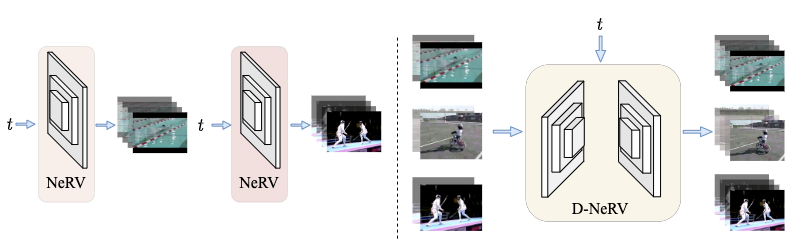
Towards Scalable Neural Representation for Diverse Videos
Bo He, Xitong Yang, Hanyu Wang, Zuxuan Wu, Hao Chen, Shuaiyi Huang, Yixuan Ren, Ser-Nam Lim, Abhinav Shrivastava CVPR, 2023 project page / arxiv / code We propose D-NeRV, a novel implicit neural representation based framework designed to encode large-scale and diverse videos. It achieves state-of-the-art performances on video compression. |
|
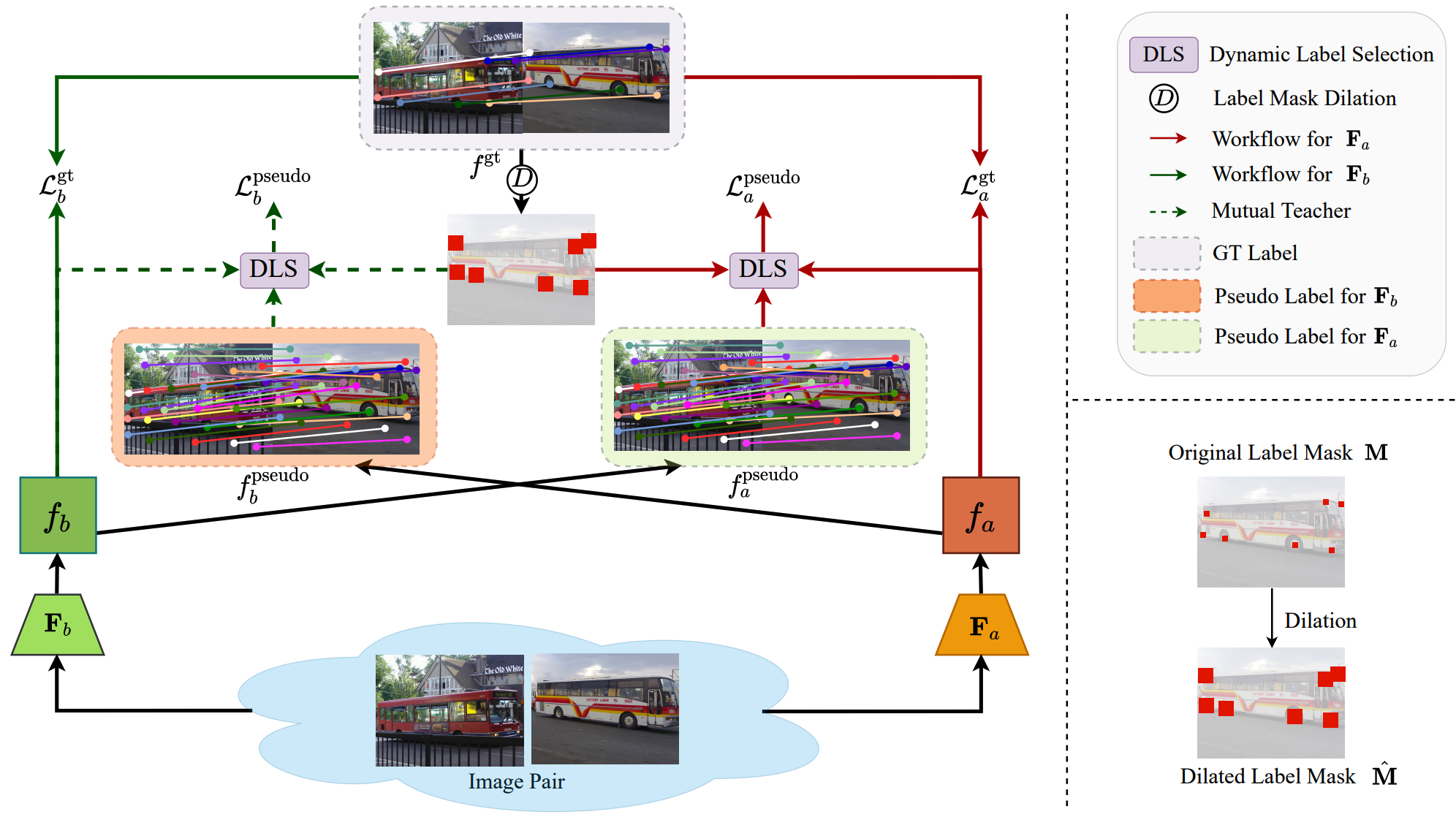
Learning Semantic Correspondence with Sparse Annotations
Shuaiyi Huang, Luyu Yang, Bo He, Songyang Zhang, Xuming He, Abhinav Shrivastava ECCV, 2022 project page / arxiv / code We address the challenge of label sparsity in semantic correspondence by enriching supervision signals from sparse keypoint annotations. We first propose a teacher-student learning paradigm for generating dense pseudo-labels and then develop two novel strategies for denoising pseudo-labels. |

|
Confidence-aware Adversarial Learning for Self-supervised Semantic Matching
Shuaiyi Huang, Qiuyue Wang, Xuming He PRCV, 2020 arxiv / code This paper explores a confidence-aware adversarial learning framework to enhance self-supervised semantic matching with improved robustness and accuracy. |
|
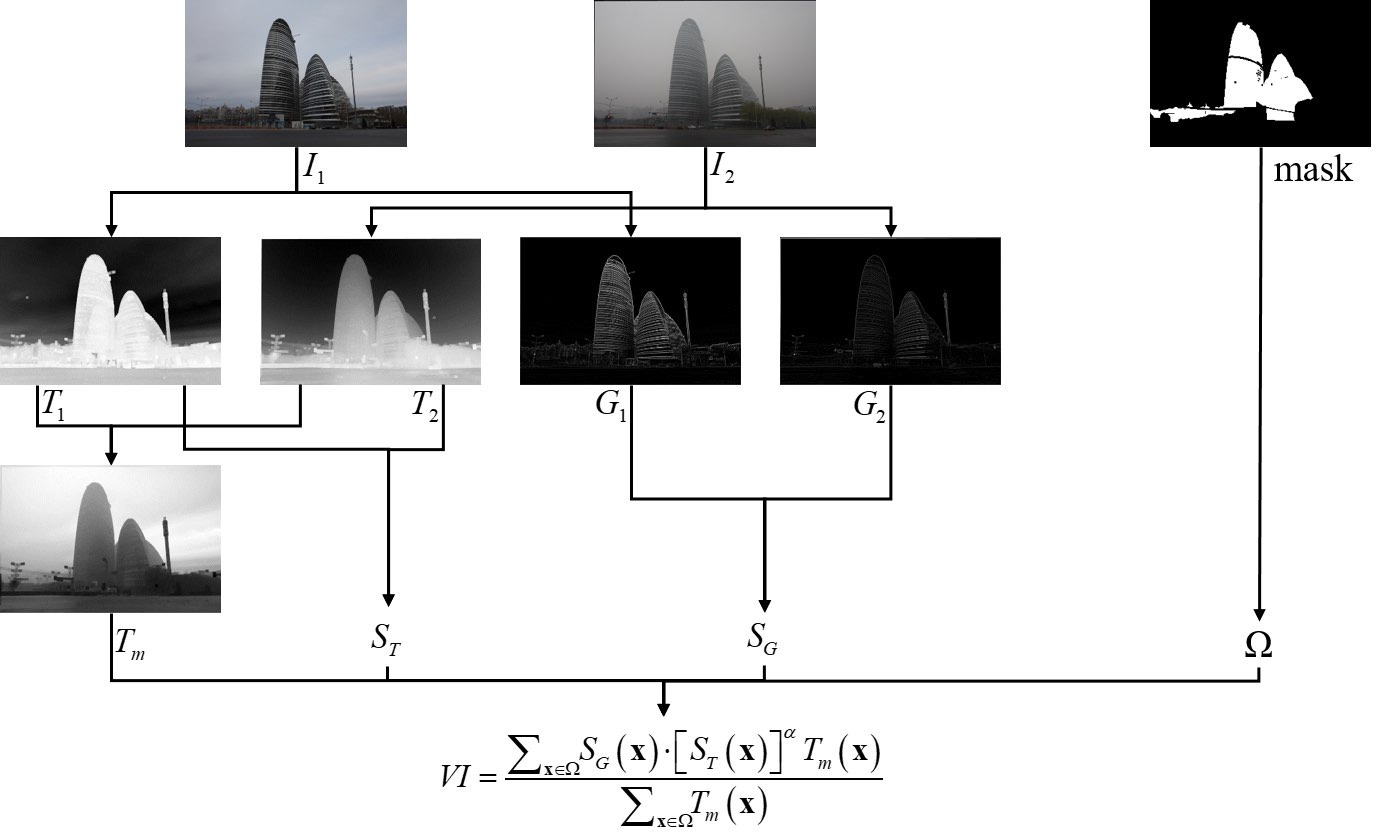
Dehazing Evaluation: Real-World Benchmark Datasets, Criteria, and Baselines
Shiyu Zhao, Lin Zhang, Shuaiyi Huang, Ying Shen, Shengjie Zhao TIP, 2020 paper / code This work presents real-world benchmark datasets, evaluation criteria, and baseline approaches for assessing dehazing methods in image processing. |
|
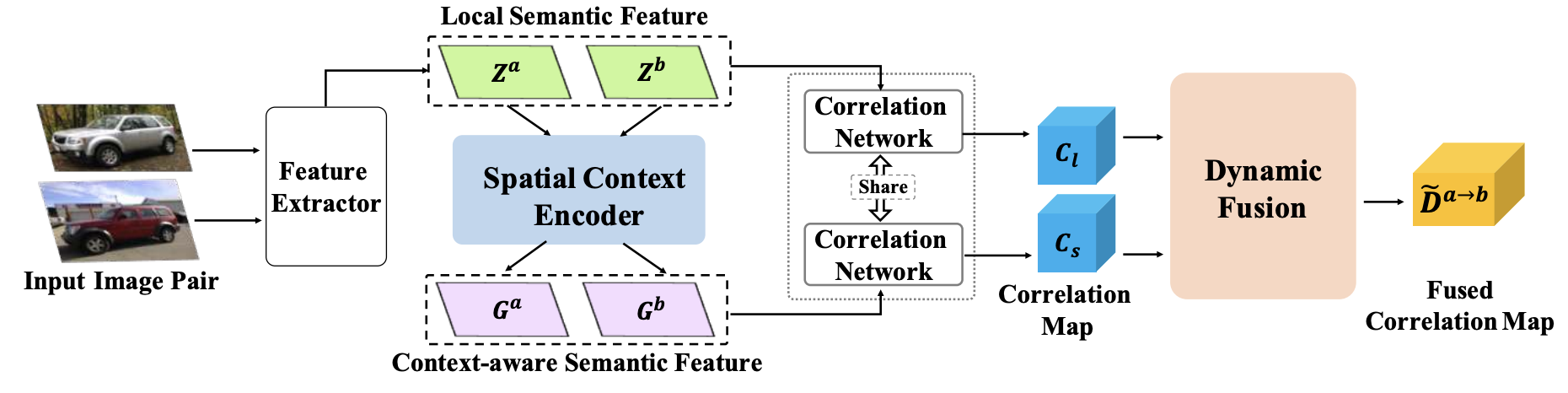
Dynamic Context Correspondence Network for Semantic Alignment
Shuaiyi Huang, Qiuyue Wang, Songyang Zhang, Shipeng Yan, Xuming He ICCV, 2019 arxiv / code We introduce a Dynamic Context Correspondence Network (DCCN) to improve semantic alignment by leveraging dynamic feature contexts across images. |

|
Evaluation of Defogging: A Real-world Benchmark Dataset, A New Criterion and Baselines
Shiyu Zhao, Lin Zhang, Shuaiyi Huang, Ying Shen, Shengjie Zhao, Yukai Yang ICME, 2019 paper / code This paper provides a real-world benchmark dataset for defogging, a new evaluation criterion, and baseline approaches to assess defogging techniques. |
|
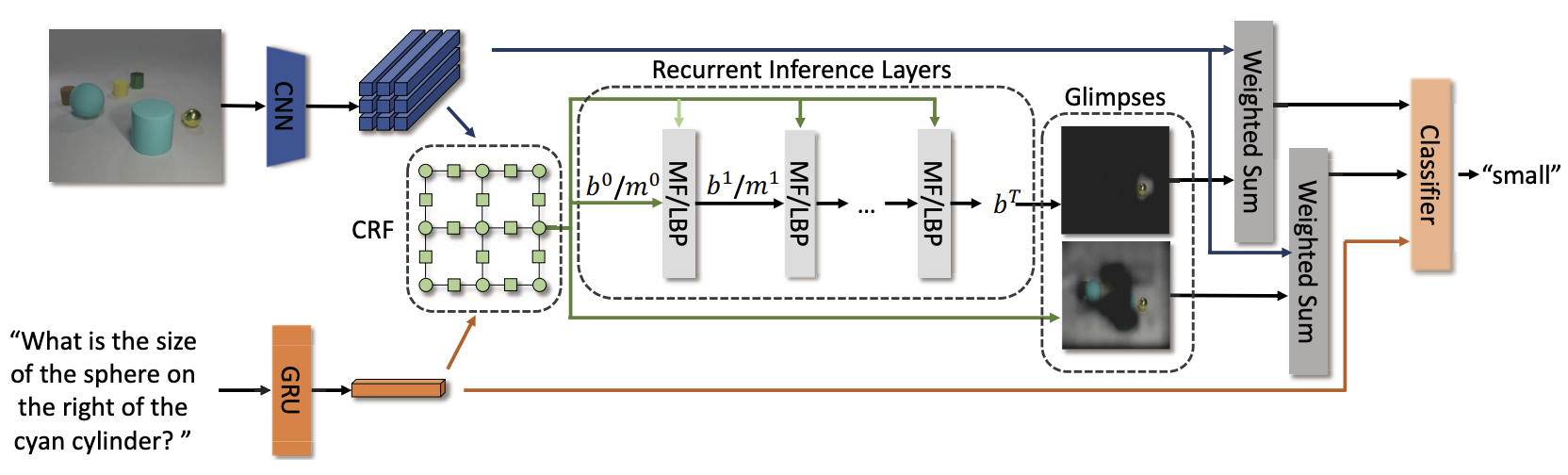
Structured Attentions for Visual Question Answering
Chen Zhu, Yanpeng Zhao, Shuaiyi Huang, Kewei Tu, Yi Ma ICCV, 2017 paper / code This work proposes structured attention mechanisms for visual question answering, enabling more precise reasoning over complex visual scenes. |
Services
|
|
Thank Dr. Jon Barron for sharing the source code of his personal page. |